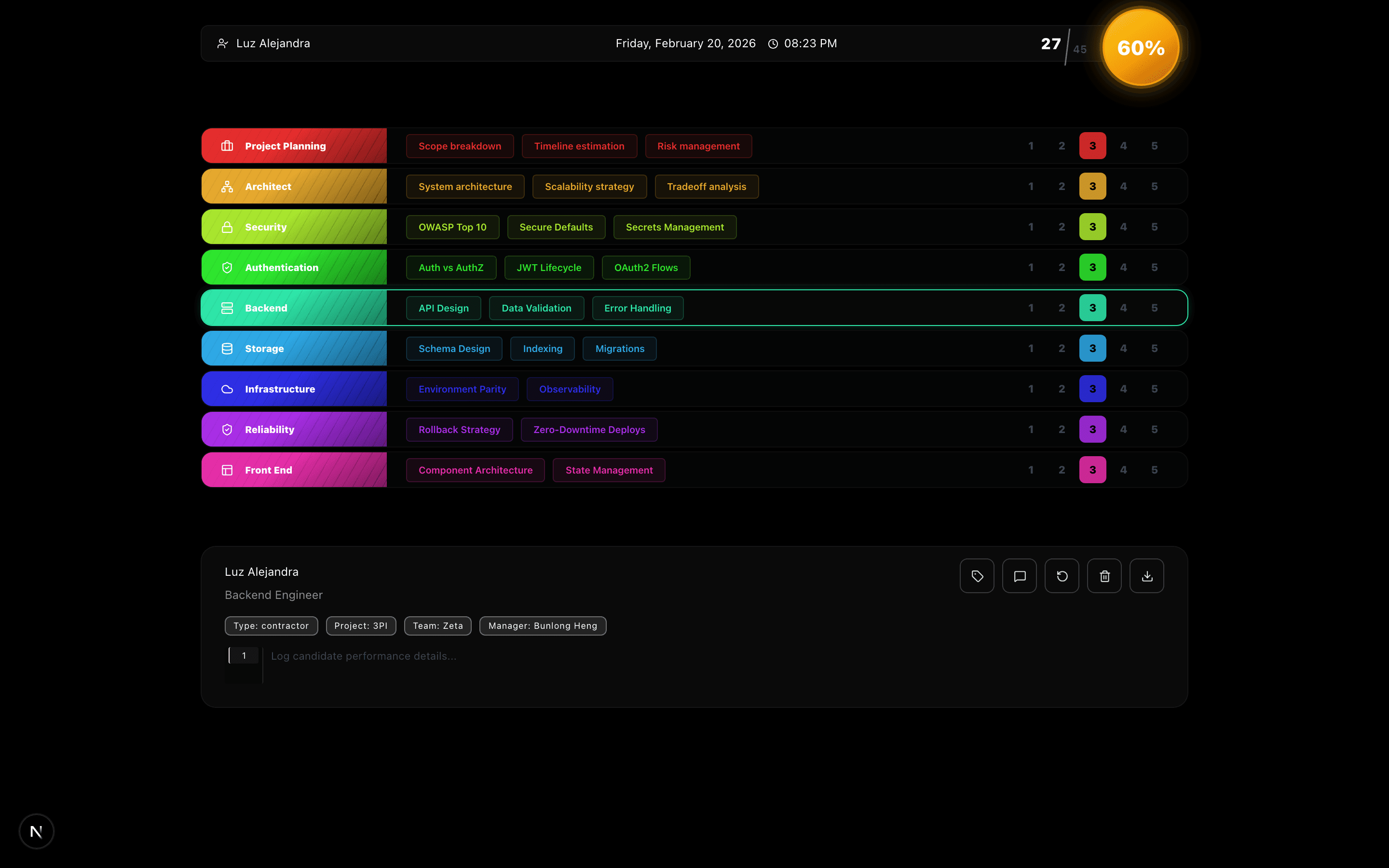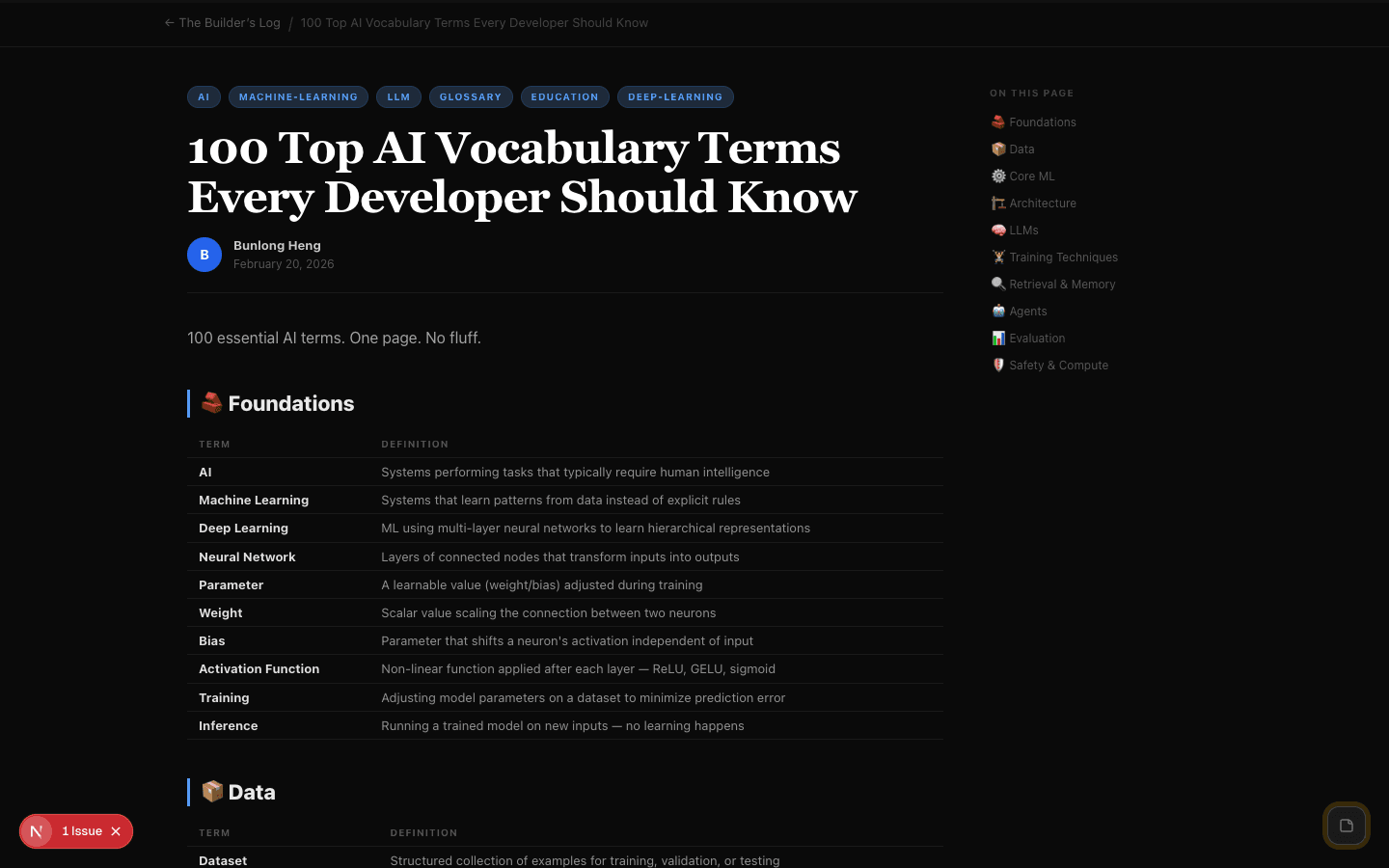
aimachine-learningllmglossaryeducationdeep-learning
100 Top AI Vocabulary Terms Every Developer Should Know
B
Bunlong Heng
February 28, 2026
100 essential AI terms. One page. No fluff.
🧱 Foundations
| Term | Definition |
|---|---|
| AI | Systems performing tasks that typically require human intelligence |
| Machine Learning | Systems that learn patterns from data instead of explicit rules |
| Deep Learning | ML using multi-layer neural networks to learn hierarchical representations |
| Neural Network | Layers of connected nodes that transform inputs into outputs |
| Parameter | A learnable value (weight/bias) adjusted during training |
| Weight | Scalar value scaling the connection between two neurons |
| Bias | Parameter that shifts a neuron's activation independent of input |
| Activation Function | Non-linear function applied after each layer — ReLU, GELU, sigmoid |
| Training | Adjusting model parameters on a dataset to minimize prediction error |
| Inference | Running a trained model on new inputs — no learning happens |
📦 Data
| Term | Definition |
|---|---|
| Dataset | Structured collection of examples for training, validation, or testing |
| Training Set | Data used to adjust model parameters |
| Validation Set | Held-out data for tuning hyperparameters and monitoring overfitting |
| Test Set | Unseen data used only to evaluate final model performance |
| Label | Ground-truth output for a training example |
| Feature | An input variable used by the model |
| Tokenization | Breaking text into tokens — roughly 4 chars or 0.75 words each |
| Token | Basic unit of text an LLM processes |
| Corpus | Large text collection used to train language models |
| Data Augmentation | Creating modified training copies to expand the dataset |
⚙️ Core ML
| Term | Definition |
|---|---|
| Loss Function | Measures how wrong predictions are — training minimizes this |
| Gradient | Direction and magnitude of steepest increase in the loss |
| Backpropagation | Computes gradients by propagating error backward through the network |
| Gradient Descent | Iteratively moves parameters in the direction that reduces loss |
| Learning Rate | Controls step size during optimization — too high = unstable |
| Batch | Subset of training examples processed before each parameter update |
| Epoch | One complete pass through the entire training dataset |
| Overfitting | Model memorizes training data and performs poorly on new data |
| Underfitting | Model too simple to capture patterns — poor on both train and test |
| Regularization | Techniques to reduce overfitting — L1/L2, dropout, early stopping |
🏗️ Architecture
| Term | Definition |
|---|---|
| Layer | Group of neurons performing the same type of transformation |
| Dense Layer | Every neuron connects to every neuron in the next layer |
| Conv Layer | Applies learned filters to local patches — great for images |
| RNN | Network with loops allowing information to persist across steps |
| LSTM | RNN variant that learns what to remember or forget long-term |
| Attention | Mechanism to weigh importance of different input parts |
| Transformer | Dominant architecture based entirely on self-attention |
| Encoder | Transformer part that reads input into contextual representations |
| Decoder | Transformer part that generates output tokens autoregressively |
| Residual Connection | Shortcut adding a layer's input to its output — aids deep training |
🧠 LLMs
| Term | Definition |
|---|---|
| LLM | Large Transformer trained on massive text — GPT, Claude, Gemini |
| Context Window | Max tokens an LLM processes at once — its working memory |
| Prompt | Input text guiding an LLM's response |
| Completion | Text generated by an LLM in response to a prompt |
| Temperature | Sampling randomness — low = deterministic, high = creative |
| Top-p | Samples from tokens whose cumulative probability exceeds p |
| Top-k | Restricts sampling to the k most probable next tokens |
| Greedy Decoding | Always picks the single most probable next token |
| Beam Search | Keeps multiple candidate sequences; picks the globally best one |
| Perplexity | How well an LLM predicts text — lower is better |
🏋️ Training Techniques
| Term | Definition |
|---|---|
| Pre-training | Large-scale training on broad data — builds general capabilities |
| Fine-tuning | Further training on a smaller task-specific dataset |
| Transfer Learning | Using a pre-trained model as a starting point for a new task |
| RLHF | Humans rank outputs → reward model → LLM optimized against it |
| DPO | Directly trains on human preference pairs — simpler than RLHF |
| LoRA | Fine-tunes small adapter matrices added to frozen weights |
| QLoRA | LoRA on a quantized model — fine-tunes on consumer GPUs |
| Instruction Tuning | Fine-tuning on (instruction, response) pairs to follow directions |
| PEFT | Parameter-Efficient Fine-Tuning — LoRA, adapters, prefix tuning |
| Distillation | Training a small student model to mimic a large teacher model |
🔍 Retrieval & Memory
| Term | Definition |
|---|---|
| RAG | Augments LLM with retrieved documents at inference time |
| Vector Database | Stores embeddings for fast nearest-neighbor search |
| Embedding | Dense numerical representation where similarity = proximity |
| Semantic Search | Search by meaning rather than keyword overlap |
| Chunking | Splitting documents into pieces for embedding and retrieval |
| Context Stuffing | Putting all relevant info directly into the prompt |
| Long-Context Model | LLM with 100k+ token window for entire documents |
| Memory (agents) | Mechanisms to persist info across turns — context or external storage |
🤖 Agents
| Term | Definition |
|---|---|
| AI Agent | Autonomously plans, uses tools, and pursues goals over multiple steps |
| Tool Use | LLM calling external functions — search, code exec, APIs, files |
| Function Calling | LLM outputs structured JSON to invoke predefined functions |
| ReAct | Prompting pattern: alternate reasoning steps with action calls |
| Chain-of-Thought | Model outputs intermediate reasoning before a final answer |
| Agentic Loop | Observe → think → act → observe. Repeats until goal is achieved |
| Multi-Agent | Multiple agents collaborating — orchestrator + worker agents |
| MCP | Open standard connecting AI models to tools and data sources |
| Subagent | Agent spawned by an orchestrator to handle a specific subtask |
| Scaffolding | Infrastructure managing an agent's loop, tools, context, memory |
📊 Evaluation
| Term | Definition |
|---|---|
| Benchmark | Standardized test suite to compare model capabilities |
| MMLU | 57-subject knowledge benchmark — law, medicine, math, etc. |
| HumanEval | Coding benchmark — models write Python functions, pass unit tests |
| Hallucination | LLM confidently generates false info not grounded in data |
| Grounding | Connecting outputs to verifiable facts to reduce hallucination |
| Precision | Of all positive predictions, what fraction are actually correct |
| Recall | Of all actual positives, what fraction did the model find |
| F1 Score | Harmonic mean of precision and recall |
| BLEU | Translation metric — measures n-gram overlap with reference text |
| ROUGE | Summarization metric — measures n-gram recall vs reference text |
🛡️ Safety & Compute
| Term | Definition |
|---|---|
| Alignment | Ensuring AI pursues goals consistent with human values |
| Constitutional AI | Anthropic's method — model critiques itself using a set of principles |
| Red Teaming | Adversarially probing a model to find failure modes before deployment |
| Jailbreak | Prompt that bypasses a model's safety guardrails |
| Prompt Injection | Malicious content in retrieved data hijacks agent instructions |
| Bias | Systematic prediction errors correlated with sensitive attributes |
| Interpretability | Understanding what's happening inside a model's computations |
| GPU | Parallel hardware essential for deep learning training |
| TPU | Google's custom AI accelerator chip for large-scale Transformer training |
| Quantization | Reducing weight precision (float32 → int8) to shrink model size |
| Inference Serving | Infrastructure hosting a model for prediction requests at scale |
| Scaling Law | Model performance improves predictably with more params, data, compute |
Comments
Be the first to leave a comment.
Related Posts